In this post, I will make an introduction on the process of creating ADaM (Analysis Data Model) , CDISC documents and then make a summary of some tips.
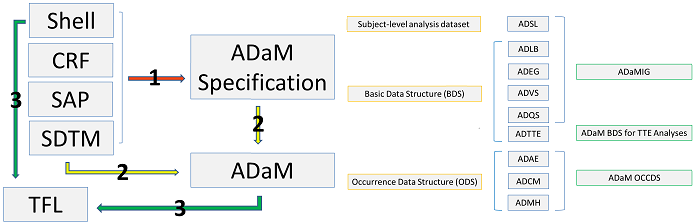
Flowchart of ADaM Development
First of all, we have to look at table shell and determines what information is needed. Then search related information from in CRF and SDTM. If there is already a variable containing this required information, we can copy variables from SDTM into ADaM directly. Otherwise, we have to establish a rule that can be used to derive ADaM variable from SDTM. These rules regarding how to get ADaM varaibles have to be written into ADaM Specification. Sometimes, we also have to check SAP (Statistical Analysis Plan) for rules such as how to impute for missing data. The rules from SAP have also to be written into ADaM Specification. With ADaM Specification and SDTM datasets available, we can start programming ADaM. The developed ADaM can be used to create TFL (Table, Figure and Listing).

CDISC Standards for ADaM
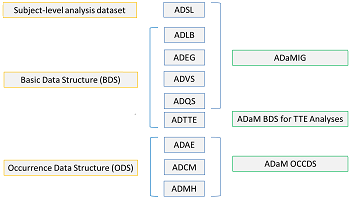
Here is where you can find all the documents. ADaMIG (ADaM Implementation Guide) describles the organization, structure and format of analysis datasets and related metadata (another name is ADaM Specification). Two types of data stuctures – the subject-level analysis dataset (ADSL) and the Basic Data Structure (BDS) – are included in ADaMIG. And the third one which is OCCDS (Occurrence Data) is described in document titled “ADaM structure for Occurrence Data”. From this webpage, you can also find document titled “ADaM Basic Data Structure (BDS) for Time-to-Event (TTE) Analyses”. This document is useful when developing ADTTE domain. In order to download these files, you have to register first. Below figure listed name and structure of several common domains. In the right part of the figure, I also listed the corresponding document. For example, ADTTE domain is a BDS domain and you have to read document – ADaM BDS for TTE Analyse.
Programming Tips for Common Issues
Time Imputation
For domains such as ADAE and ADCM, we may have to create flag variables like TRTEMFL and ONTRT. Variable label for TRTEMFL is “Treatment Emergent Analysis Flag”. This variable is to be used for any analysis of treatment-emergent AEs. The derivation is something like below:
| If ADSL.TRTSDT <= ADAE.ASTDT <=ADSL.TRTEDT + x days then TRTEMFL = “Y” |
Label for ONTRTFL is “On-Treatment Flag”. It is to be used to indicate whether the record occurred while the subject was on treatment. Here is an example derivation:
| If ADSL.TRTSDT <= ADCM.ASTDT <= ADSL.TRTEDT then ONTRTFL = ‘Y’ |
Usually TRTSDT and TRTEDT will not be missing as long as the study has been completed. But AESTDTC or CMSTDTC may be completely missing or partial missing sometimes. This may lead to missing of ASTDT(Analysis Start Date) and thus we cannot make comparison. For most studies, timing imputation will be applied and imputation rules will be included in SAP. And due to complexity of real study, we may also have to impute AENDT (Analysis Stop Date). Supose that we have following rules for ASTDT and AENDT in ADCM domain:
| If start date is completely missing, start date will have 2005 imputed for year, Jananuary for the missing month and 1 for the missing day. If month and date are missing, we will use Janauary to impute the missing month and 1 to impute the missing date. If only date is missing, we will use the 1 to impute missing date. If stop date is completely missing, start date will have 2015 imputed for year, December for the missing month and 31 for the missing day. If month and date are missing, we will use December to impute the missing month and 31 to impute the missing date. If only date is missing, we will use the last of day of that month to impute missing date. |
We can use following code to make imputation. It is very easy except for AENDT imputation when only date is missing and the month is February. Because February has 29 days for leap year and 28 days for all remaning years. The key thing here is to determine whether a year is leap year or not. For year whose number is divisible by 4 and not divisible by 100, we can say that this year is leap year. If the year can be divisible by 400, we also consider this year to be a leap year. Please note that you can also use FORMAT to populate last day of other months. It can simplify your code.
Click here to hide/show code
if cmstdtc eq “” then do;
astdtc = “2005-01-01”;
astdtf = “Y”;
end;
if cmstdtc ne “” then do;
if length(strip(cmstdtc)) = 10 then do;
astdtc = strip(cmstdtc);
astdtf = “”;
end;
if length(strip(cmstdtc)) = 4 then do;
astdtc = strip(cmstdtc)||”-01-01″;
astdtf = “M”;
end;
if length(strip(cmstdtc)) = 7 then do;
astdtf = “D”;
astdtc = strip(cmstdtc)||”-01″;
end;
end;
astdt = input(astdtc,yymmdd10.);
*Impute for AENDT;
if cmendtc eq “” then do;
aendtc = “2015-12-31”;
aendtf = “Y”;
end;
if cmendtc ne “” then do;
if length(strip(cmendtc)) = 10 then do;
aendtc = strip(cmendtc);
aendtf = “”;
end;
if length(strip(cmendtc)) = 4 then do;
aendtc = strip(cmendtc)||”-12-31″;
aendtf = “M”;
end;
if length(strip(cmendtc)) = 7 then do;
aendtf = “D”;
if strip(scan(cmendtc,2,”-“)) = “01” then aendtc = strip(cmendtc)||”-31″;
if strip(scan(cmendtc,2,”-“)) = “03” then aendtc = strip(cmendtc)||”-31″;
if strip(scan(cmendtc,2,”-“)) = “04” then aendtc = strip(cmendtc)||”-30″;
if strip(scan(cmendtc,2,”-“)) = “05” then aendtc = strip(cmendtc)||”-31″;
if strip(scan(cmendtc,2,”-“)) = “06” then aendtc = strip(cmendtc)||”-30″;
if strip(scan(cmendtc,2,”-“)) = “07” then aendtc = strip(cmendtc)||”-31″;
if strip(scan(cmendtc,2,”-“)) = “08” then aendtc = strip(cmendtc)||”-31″;
if strip(scan(cmendtc,2,”-“)) = “09” then aendtc = strip(cmendtc)||”-30″;
if strip(scan(cmendtc,2,”-“)) = “10” then aendtc = strip(cmendtc)||”-31″;
if strip(scan(cmendtc,2,”-“)) = “11” then aendtc = strip(cmendtc)||”-30″;
if strip(scan(cmendtc,2,”-“)) = “12” then aendtc = strip(cmendtc)||”-31″;
if strip(scan(cmendtc,2,”-“)) = “02” then do;
if (mod(input(strip(scan(cmendtc,2,”-“)),best.),4) = 0
and mod(input(strip(scan(cmendtc,2,”-“)),best.),100) ne 0) or
mod(input(strip(scan(cmendtc,2,”-“)),best.),400) = 0 then aendtc = strip(cmendtc)||”-29″;
else aendtc = strip(cmendtc)||”-28″;
end;
end;
end;
aendt = input(aendtc,yymmdd10.);
ABLFL, BASE and CHG
For BDS domains such as ADLB, ADEG or ADVS, we may need to create a Baseline Record Flag variable ABLFL. It is to be used for identifying the baseline record for each subject, parameter. For each subject and each parameter, the latest non-missing record before start date of treatment will be identified as Baseline record. The most commonly related variables are BASE and CHG. BASE is AVAL from Baseline analysis record. CHG is to indicate change from baseline analysis value and equal to AVAL – BASE. I know that a lot of people compute BASE at first and then merge BASE back before computing CHG. It is annoying and I don’t like using MERGE too much. Here is and I strongly recommend you to use RETAIN statement.
Suppose that we have a data named ADLB1. We can create a flag variable FF which will be populated as Y if the analysis observation occurred before start date of treatment. For other observations, FF will be populated as missing. Sort this data by USUBJID, PARCAT1, PARAM, FF and ADT. Observations meeting condition LAST.FF and FF = “Y” are exactly the Baseline analysis observations.
Click here to hide/show code
*ABLFL;
data adlb2;
set adlb1;
if (. < adt < trtsdt) then ff = “Y”;
else ff = “”;
if aval eq . and avalc eq “” then ff = “”;
run;
proc sort data = adlb2; by usubjid parcat1 param ff adt; run;
data adlb2(drop=ff);
set adlb2;
by usubjid parcat1 param paramcd ff adt;
if ff = “Y” and last.ff then ablfl = “Y”;
run;
After we get the baseline analysis record, we can sort the data by USUBJID, PARCAT1, PARAM and DESCENDING ABLFL at first. Then use RETAIN statement to get BASE.
Click here to hide/show code
*base;
proc sort data = adlb2; by usubjid parcat1 param descending ablfl; run;
data adlb3;
retain base;
set adlb2;
by usubjid parcat1 param descending ablfl;
if first.param and ablfl ne “Y” then base = .;
if ablfl =”Y” then base = aval;
run;
Similar method can be used to derive post baseline flag variable (POSTFL). Why do we need to derive POSTFL? That is because CHG is only populated for post baseline records for most studies. Here we created a tempary variable POSTFL_. It will be populated as Y for both baseline analysis observation and all post baseline analysis observations. Records having ABLFL equal to null and POSTFL_ equal to Y are exactly what we want – post baseline records only for which CHG will be populated.
Click here to hide/show code
*postfl & Chg;
proc sort data = adlb3; by usubjid parcat1 param adt; run;
data adlb3(drop=postfl_);
retain postfl_;
set adlb3;
by usubjid parcat1 param adt;
if ablfl =”Y” then postfl_ = “Y”;
if first.param and ablfl = “” then postfl_ = “”;
if first.param and ablfl = “Y” then postfl_ = “Y”;
if postfl_ = “Y” and ablfl ne “Y” then postfl = “Y”;
if aval ne . and base ne . and postfl = “Y” then chg = aval – base;
run;
PARAMN
PARAMN is a numeric representation of PARAM. There must be a one-to-one mapping to PARAM within a dataset. IF…ELSE IF… can be used to populate PARAMN. But what if there are a lot of parameters? The code will be lengthy and we may also have to update code as time goes on and more data are collected. Here we can use FORMAT and update format if new parameters emerge.
Click here to hide/show code
proc format;
invalue paramn
“ALB” = 1001
“ALP” = 1002
“ALT” = 1003
;
quit;
data adlb;
paramcd = “ALB”; output;
paramcd = “ALP”; output;
paramcd = “ALT”; output;
run;
data adlb ;
set adlb ;
paramn = input(paramcd, paramn.);
run;
DTYPE
For some studies, we may have to derive a new record which contains the mean of AVAL from all observations of a given paramter. In this case, I also recommend you to use RETAIN statement. Similar approach can be used to derive PARAMTYP.
Click here to hide/show code
proc sort data = adlb; by usubjid parcat1 param adt; run;
data adlb;
retain sum n;
set adlb;
by usubjid parcat1 param adt;
if first.param then do;
sum = 0;
n = 0;
end;
sum + aval;
n + 1;
if last.param;
aval = sum/n;
dtype = “AVERAGE”;
run;
Like the post? Welcome to share or you can subscribe to get latest post. How to subscribe? Go to the top-right corner of this web page to submit your name and email address. If you cannot receive emails from us, please check your spam/junk folder.
