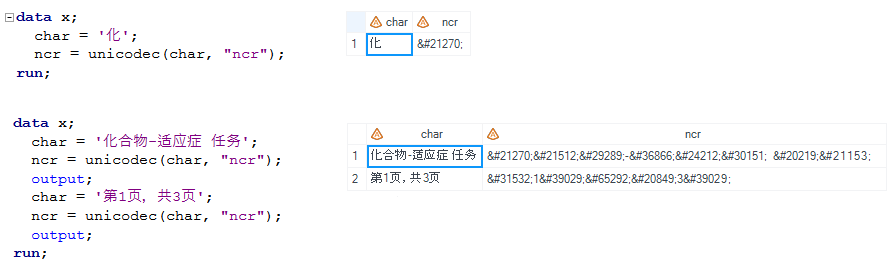
Perhaps you already noticed that a single Chinese character is displayed using a sequence of characters (like \u34920; for 表) When generating TFL in Chinese. This kind of sequence of characters is called Numeric Character Reference (NCR). It is difficult if we want to post-manipulate RTF code especially when we’d like to add new Chinese characters into TFL or even try to translate Chinese characters in TFL to another language like English. This post will describe several concepts of NLS (National Language Support) feature which can help you better understand encoding and then introduce two functions that can help you make the mapping between code and character. The method described here also works for Japanese and Korean.
Overview
Companies are globalizing and consolidating systems from various parts of the world and thus software must be able to handle characters of several languages. Fortunately, SAS provides NLS (National Language Support) features to ensure that users in region such as Asia and Europe to process data successfully in their native languages and environments. National characters which are specific to a particular nation or group of nations can be displayed and printed properly in SAS.
Speaking of NLS, encoding is topic that must be avoided. An encoding maps each character in a character set to a unique numeric representation, which results in a table of all code points. A character set is the set of characters and symbols that are used by a language or group of language. It includes national characters (specific to a particular nation of group of nations), special characters (like punctuation marks), unaccented Latin characters A-Z, digits 0-9 and control characters (needed by computer).
An encoding method is a set of rules that can assign numeric representations to a set of characters. It prescribes the number of bits required for storing the numeric representation of a specific character and its code position in the encoding. Common encoding methods include Unicode, UTF-8, UTF-16, UTF-32, ASCII, EBCDIC family, ISO, ISO 8859 Family and Windows family.
Concepts of Character Set and Encoding
SBCS and DBCS
SBCS (Single Byte Character Set) is used to refer to character encodings that use exactly one byte for each graphic character. The maximum number of characters that can be represented with one byte is 256. For DBCS (Double Byte Character Set), either all characters (including control characters) are encoded in two bytes, or merely graphic character not representable by an accompanying single-byte character set (SBCS) is encoded in two bytes. DBCS can represent up to 65, 536 characters and supports national languages like Chinese and Japanese which contains a large number of unique characters or symbols. Korean Hangul also uses two bytes per character.
Unicode: UTF-8, UTF-16 and UTF-32
Unicode is a computing industry standard for consistent encoding, representation, and handling of text expressed in most of the world’s writing systems. The standard is maintained by the Unicode Consortium and the recent version, Unicode 12.1, released in May 2019 contains 137, 994 characters. This standard defines UTF-8, UTF-16, UTF-32 and several other encodings. Most commonly used encodings are UTF-8 and UTF-16.
UTF-8 uses one byte (8-bit) for the first 128 code points and up to 4 bytes for other characters. The first 128 Unicode code points represent the ASCII characters which means that any ASCII text is also a UTF-8 text. UTF-16 uses two bytes (16-bit) encoding for basic multilingual plane and a 4-byte encoding for the other planes. UTF-32 uses four bytes for each character. UTF-32 is able to encode all Unicode code points. However, it is not widely used because each character uses four bytes and takes significantly more space than other encodings.
EUC
EUC (Extended Unix Code) is a multi-byte character encoding system used primarily for Japanese, Korean and Simplified Chinese. EUC-CN uses GB2312 standard for simplified Chinese characters. GB abbreviates Guojia Biaozhun (国家标准), which means national standard in Chinese. GBK is an extension to GB2312 and GB18030 defines an extension of GBK and capable of encoding the entirety of Unicode. EUC-JP is a variable-width encoding used to represent elements of three Japanese character set standards, namely JIS X 0208, JIS X 0212 and JIS X 0201. EUC-KR is a variable-width encoding to represent Korean text.
NCR
NCR (Numeric Character Reference) is a common markup construct used in SGML (standard Generalized Markup Language) and SGML-derived markup languages. It consists of a short sequence of characters that, in turn, represents a single character.
Encoding and Transcoding
Encoding establishes the default working environment for your SAS session while transcoding is the process of converting data from one encoding to another. Each SAS session is set to a default encoding. It is determined by several SAS language elements. Transcoding is necessary when the SAS session encoding is different from the encoding of dataset. It usually happens when you move data between operating environments that use different locales and encoding. Note that transcoding is a not a translation between languages. It only maps characters. Following lists SAS options that can transcode SAS data. Those highlighted in yellow are most popularly used.
| Option | Where Used |
| CHARSET= | ODS MARKUP statement |
| CORRECTENCODING= | MODIFY statement of the DATASETS procedure |
| ENCODING= | %INCLUDE, FILE, FILENAME, INFILE, ODS statements; FILE and INCLUDE commands |
| ENCODING= | in a DATA step |
| INENCODING= | LIBNAME statement |
| ODSCHARSET= | LIBNAME statement for XML |
| ODSTRANTAB= | LIBNAME statement for XML |
| OUTENCODING | LIBNAME statement |
| XMLENCODING= | LIBNAME statement for XML |
SAS FUNCTION UNICODEC
Here is an example of table created in Chinese.
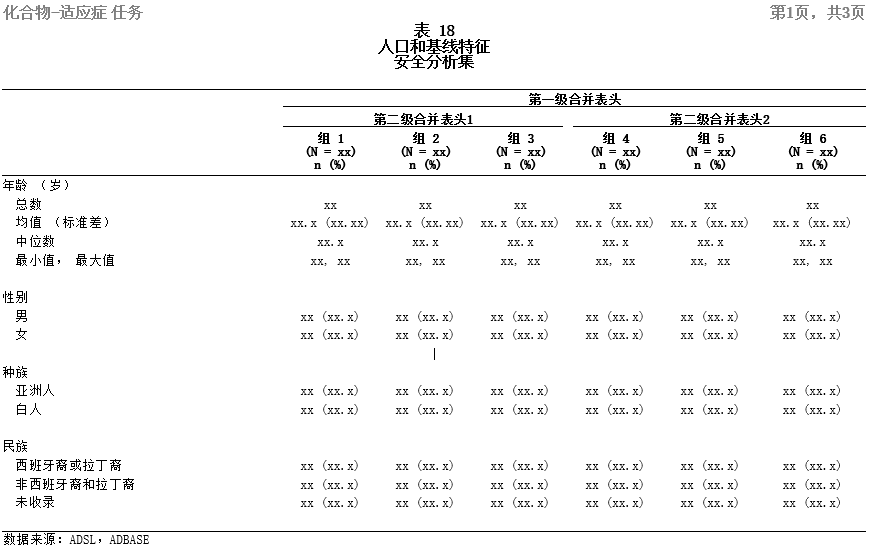
Above title of looks like below when opening the table in Notepad++ or converting the table into SAS dataset. You cannot see any Chinese characters. The first Chinese character “表” is represented by \u34920;.
![]()
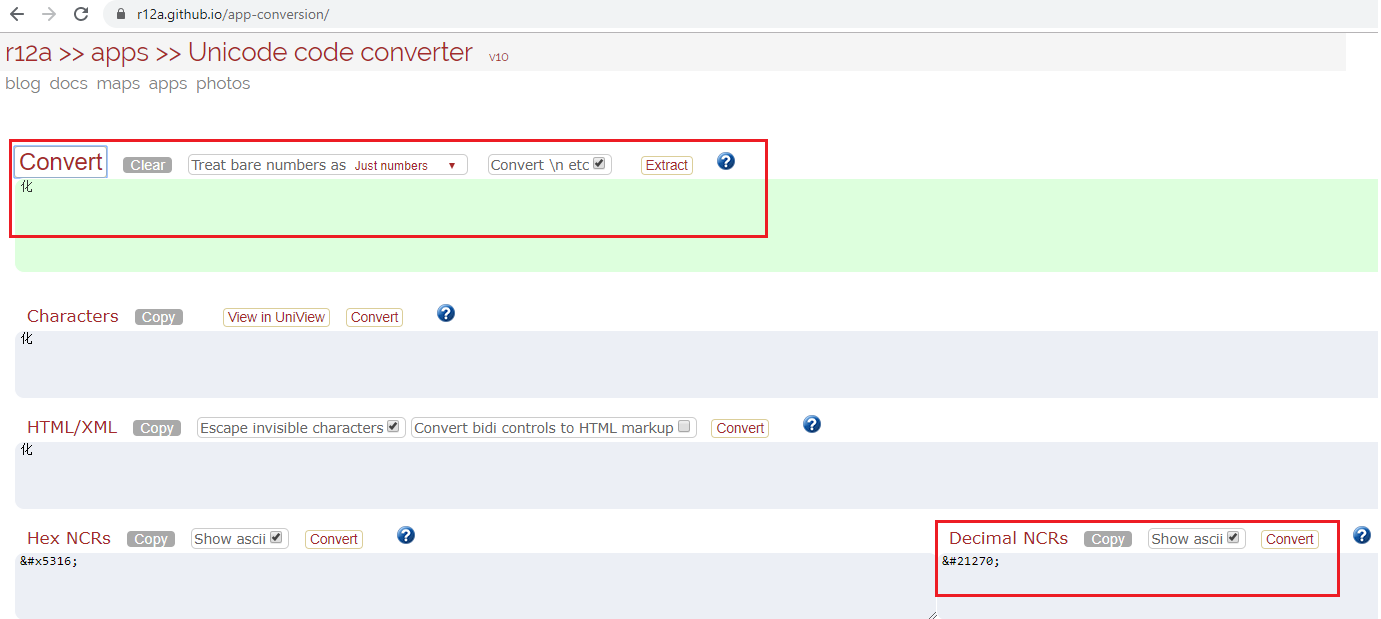
If we want to add the first title (in gray) in page header area, we need to know the numeric character set of “化合物-适应症 任务” and “第1页,共3页”. A webpage (https://r12a.github.io/app-conversion/) can do the conversion. Here shows NCR for “化”. However, it is not convenient if we want to develop a reporting macro that can be used widely.
To make the macro more flexible, function UNICODEC can be used. It can convert characters in the current SAS session encoding to Unicode characters.
| Syntax:
STR=UNICODEC(<instr> (,<Unicode type> )) str: data string that has been converted to Unicode encoding instr: input string Unicode type: Unicode character formats (see below) |
|
| ESC | Unicode Escape (\u0042) |
| NCR | Numeric Character Representation (大) |
| PAREN | Unicode Parenthesis Escape <u0061> |
| UTF8 | UTF8 encoding |
| UTF16 | UTF16 encoding with big endian. UCS2 is an alias |
| UTF16B | UTF16 encoding with big endian. UCS2B is an alias |
| UTF16L | UTF16 encoding with big endian. UCS2L is an alias |
| UTF32 | UTF32 encoding with big endian. UCS4 is an alias |
| UTF32B | UTF32 encoding with big endian. UCS4B is an alias |
| UTF32L | UTF32 encoding with big endian. UC42L is an alias |

SAS FUNCTION UNICODE
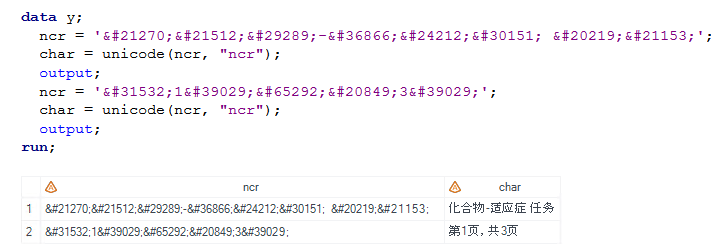
Once upon a time, a friend asked me how to convert these NCR into Chinese character in SAS dataset since they would like to translate Chinese TFL into English TFL. In this case, function UNICODE can be used.
| Syntax:
STR=UNICODE(<instr> (,<Unicode type> )) str: data string that has been converted to current SAS session encoding instr: input data string Unicode type: Unicode character formats (see below) |
|
| ESC | Unicode Escape (\u0042) |
| NCR | Numeric Character Representation (大) |
| PAREN | Unicode Parenthesis Escape <u0061> |
| UTF8 | UTF8 encoding |
| UTF16 | UTF16 encoding with big endian. UCS2 is an alias |
| UTF16B | UTF16 encoding with big endian. UCS2B is an alias |
| UTF16L | UTF16 encoding with big endian. UCS2L is an alias |
| UTF32 | UTF32 encoding with big endian. UCS4 is an alias |
| UTF32B | UTF32 encoding with big endian. UCS4B is an alias |
| UTF32L | UTF32 encoding with big endian. UC42L is an alias |