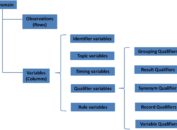
Text strings that exceed the maximum length of variables should be handled per the instructions in section 4.1.5.3 of SDTM 3.2. Per the instructions, we sometimes need to split long text strings and split one variable into multiple variables. Before introducing how to split variables using SAS, let’s look at variables which may have long text and corresponding conventions.
4 Conventions from SDTMIG 3.2
Generally speaking, test description (–TEST) is normally limited to 40 characters. This convention should also be applied to the Qualifier Value Label (QLABEL) in Supplemental Qualifiers (SUPP–) datasets. The reason is that –TEST variable is meant to serve as a label for a –TESTCD when Findings dataset is transposed to a horizontal format. Similarly, QLABEL variable is meant to serve as a label for QVAL variable. And the length of label cannot be greater than 40. If test description (—TEST) is longer than 40 characters, we have choice to either insert the first 40 characters or a text string abbreviated to 40 characters in —TEST (see section 4.1.5.3.1).
As for this convention, there are exceptions. IETEST values in IE and TI are limited to 200 characters instead of 40 characters due to the fact that ITEST values are not expected to be transformed to column labels. IETEST is to be used only for the verbatim description of the inclusion or exclusion criteria. If the text is less than or equal to 200 characters, it goes to IETEST; if the text is greater than 200 characters, put meaningful text in IETEST and describe the full text in SUPPIE domain. This convention is the same for both IE and TI domains (see section 6.3 and section 7.4).
For some variables such as MHTERM, DVTERM and AEACNOTH, LB/EG abnormality interpretation, there is a convention to handle the situation where data values are longer than 200 characters. Usually, the first 200 characters of text should be stored in the standard domain variable and each additional 200 characters of text should be stored as a record in the SUPP– datasets. In the SUPP– dataset, the value for QNAM should contain a sequential variable name. The sequential variable name is formed by appending a one-digit integer, beginning with 1, to the original standard domain variable name. For example, if the text length for MHTERM is 500, we should put the first 200 characters of text in the standard domain variable and dataset (MHTERM in MH), the next 200 characters of text as a first supplemental record (QNAM = “MHTERM1”) in SUPPMH dataset and the final 100 characters of text as a second record (QNAM = “MHTERM2”) in the SUPPMH dataset. Here I have to remind you that the text should be split between words to improve readability when splitting a text string into several records. Pleas also remember to replace the last character with a digit when the standard domain variable name is already 8 characters in length. For example, the QNAM for the SUPPAE should have values AEACNOT1, AEACNOT2, and so on for AEACNOTH in AE domain. This convention applies to all domains based on a general observation class (see section 4.1.5.3.2).
Comments domain is not based on generation class and has different rules. When the comment text if longer than 200 characters, the first 200 characters of the comment will go to in COVAL, the next 200 characters go to COVAL1 and additional text will be stored in COVAL3, COVAL4 … COVALn as needed. This convention has nothing to do with SUPPCO (see section 5). If TSVAL is > 200 characters, then it should be split into multiple variables, TSVAL-TSVALn. This is similar to that used for CO domain (see section 7.4).
SAS macro that can be applied to split long text strings
By running following code, we can create a DV dataset which has a value text (for DVTERM) longer than 200 characters.
Click here to hide/show code
data dv;
length dvterm $300.;
dvterm = “According to the protocol, PK
samples must be stored at –
70°C±10°C until shipment. All
whole blood and plasma PK
samples for the Period 4 time
points, Hour -24.08 through Hour
5.00 were out of range on 25-
September-2009, reaching a
high of -58°C for approximately
3.5 hours.”;
run;
This is dummy data that we will use to test our macro later.
 This section provides you a maro with 4 parameters. The first parameter is for source dataset which contains variable that needs to be split. In our case, it will set to be DV. Here I have to remind you that the output dataset has the same name with the source dataset. The second parameter is for source variable (DVTERM for this example) which will be split into multiple parts. The third parameter determines the length (200 here) of the sub part. If you want to split a long text string into multiple parts which is not greater than 80 characters, the value of len should be 80. Finally, how about the last parameter? It will determine the output result.
This section provides you a maro with 4 parameters. The first parameter is for source dataset which contains variable that needs to be split. In our case, it will set to be DV. Here I have to remind you that the output dataset has the same name with the source dataset. The second parameter is for source variable (DVTERM for this example) which will be split into multiple parts. The third parameter determines the length (200 here) of the sub part. If you want to split a long text string into multiple parts which is not greater than 80 characters, the value of len should be 80. Finally, how about the last parameter? It will determine the output result.Click here to hide/show code
%macro msplit(dat = , var = , len = , typ = );
%if &typ = 1 %then %do;
data &dat(drop = &var._ temp temp1 temp2 n m j new);
length new &var._ temp $5000.;
set &dat;
m = length(&var);
&var._ = &var;
n = 0;
do while(n <=m);
if length(strip(&var._)) <= %eval(&len) then do;
new = &var._;
j = length(&var._);
&var = strip(new);
output;
leave;
end;
else do;
temp = substr(&var._,1,%eval(&len));
temp1 = substr(&var._,%eval(&len),1);
temp2 = substr(&var._,%eval(&len+1),1);
if temp1 = “” or (temp1 ne “” and temp2 = “”) then do;
new = substr(&var._,1,%eval(&len));
if temp1 = “” then do;
&var._ = strip(substr(&var._,%eval(&len)));
j = %eval(&len);
end;
if temp1 ne “” and temp2 = “” then do;
&var._ = strip(substr(&var._,1+%eval(&len)));
j = %eval(&len) +1;
end;
end;
else do;
j = find(temp,” “,-1*length(temp));
new = substr(&var._,1,j);
&var._ = strip(substr(&var._,j));
end;
&var = strip(new);
output;
end;
n + j;
end;
run;
%end;
%if &typ = 2 %then %do;
data &dat(drop = &var._ temp temp1 temp2 n m j new);
length new &var._ temp $5000.;
set &dat;
m = length(&var);
&var._ = &var;
new = “@”;
n = 0;
do while( n <=m);
if length(&var._) <= %eval(&len) then do;
new = strip(new)||” \line “||strip(&var._);
j = length(strip(&var._))+1;
end;
else do;
temp = substr(&var._,1,%eval(&len));
temp1 = substr(&var._,%eval(&len),1);
temp2 = substr(&var._,%eval(&len+1),1);
if temp1 = “” or (temp1 ne “” and temp2 = “”) then do;
new = strip(new)||” \line “||substr(&var._,1,%eval(&len));
if temp1 = “” then do;
&var._ = strip(substr(&var._,%eval(&len)));
j = %eval(&len);
end;
if temp1 ne “” and temp2 = “” then do;
&var._ = strip(substr(&var._,%eval(&len+1)));
j = %eval(&len+1);
end;
end;
else do;
j = find(temp,” “,-1*length(temp));
new = strip(new)||” \line “||substr(&var._,1,j);
&var._ = strip(substr(&var._,j));
end;
end;
n + j;
end;
&var = substr(new,9);
run;
%end;
%if &typ = 3 %then %do;
proc sql noprint;
select max(ceil(length(strip(&var))/&len))+1 into: num trimmed from &dat;
quit;
data &dat(drop = &var._ &var temp temp1 temp2 n m j a);
length &var._ temp $5000. &var.1-&var.&num $&len.;
set &dat;
m = length(strip(&var));
&var._ = &var;
array new{&num} &var.1-&var.&num ;
a = 1;
n = 0;
do while( n <=m);
if length(&var._) <= %eval(&len) then do;
new{a} = strip(&var._);
j = length(strip(&var._))+1;
a + 1;
end;
else do;
temp = substr(&var._,1,%eval(&len));
temp1 = substr(&var._,%eval(&len),1);
temp2 = substr(&var._,%eval(&len+1),1);
if temp1 = “” or (temp1 ne “” and temp2 = “”) then do;
new{a} = substr(&var._,1,%eval(&len));
a + 1;
if temp1 = “” then do;
&var._ = strip(substr(&var._,%eval(&len)));
j = %eval(&len);
end;
if temp1 ne “” and temp2 = “” then do;
&var._ = strip(substr(&var._,%eval(&len+1)));
j = %eval(&len+1);
end;
end;
else do;
j = find(temp,” “,-1*length(temp));
new{a} = substr(&var._,1,j);
&var._ = strip(substr(&var._,j));
a + 1;
end;
end;
n + j;
end;
if a < &num then do; drop &var.&num ; end;
run;
%let dat1 = %upcase(&dat);
proc sql noprint;
select count(*)
into :nvar
separated by ‘ ‘
from dictionary.columns
where libname = ‘WORK’ and memname = “&dat1″ and index(name,”&var”);
quit;
data &dat(drop = &var.&nvar i);
length &var &var.1-&var.%eval(&nvar-1) $&len.;
set &dat;
array old{&nvar} &var.1-&var.&nvar;
array new{&nvar} &var &var.1-&var.%eval(&nvar-1);
do i = 1 to &nvar;
new{i} = old{i};
end;
run;
%end;
%mend;
How to use the macro and final output
Following figure shows you how to use the macro and the final outputs. If you set value of typ to be 1, one observation will be converted into several rows. Each row contains one sub part.
Click here to hide/show code
In our case, the original variable was broke into two parts. The first part – put in the first row – starts from “According” and ends with “on”. The second part – the rest of the original string – was placed into the second row.

This code snippet is for the second type.
Click here to hide/show code
As you can see from Figure 3, the output variable has the same name as that of source variable. The difference is that different sub string will be concatenated with “\line”.

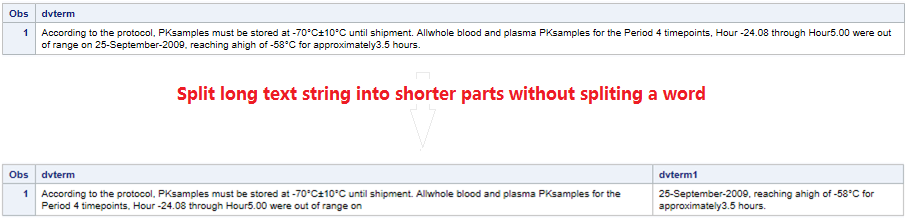
Here is for the third type and what we are seeking per SDTMIG.
Click here to hide/show code
The original source variable was converted into multiple variables – one variable having the same name with source variable and other variables having sequential variable name.