In clinical trial, we have to develop summary tables for safety measures like vital signs and laboratory examinations. Descriptive summary statistics such as the number of observations (n), mean, standard deviation (SD), median and range (minimum, maximum) for continuous variables must be computed and displayed. When dealing with these statistics, rules for significant digits are as follows: If the raw value has x decimal places, then the mean and the median will have x + 1 decimal places and standard deviation will have x + 2 decimal places. At the same time, Min and max will have x decimal places.
This rule is annoying when it comes to laboratory parameters as raw values of different laboratory values have decimal places. Programmers with less experience may use IF…ELSE IF… statement to handle this situation. The code will become very long as time goes on. Moreover, you have to change code once there are new parameters or the maximum number of digits after the decimal point for a parameter changes. Look terrible, right? This post will present you a new approach which can prevent you from checking data and updating code manually.
Get maximum number of digits after decimal point for values of each parameter
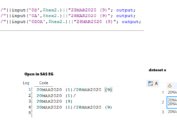
Suppose that we have a text file stored in D:\ drive and it contains data from ADLB domain.

The following program shows how to read these data using column input. The variable USUBJID is character and we read it from column 1 to column 7. Please note that $ should always be used for character variable. Variable TRT01A is read in column 9 through column 20. TRT01AN is read in column 22. PARAM and PARAMN Variable read in column 25 through 41 and column 43, respectively. AVISIT and AVISITN start from column 45 through 60 and column 62 through 65. AVALC covers column 67 through 71. AVAL is numeric and is read in column 73 through column 76.
Click here to hide/show code
data adlb;
infile “D:\ADLB.txt”;
input USUBJID $ 1-7 TRT01A $ 9-20 TRT01AN 22 PARAM $ 25-41 PARAMN 43
AVISIT $ 45-60 AVISITN 62-65 AVALC $ 67-71 AVAL 73-76;
run;
Here shows you the result SAS data.
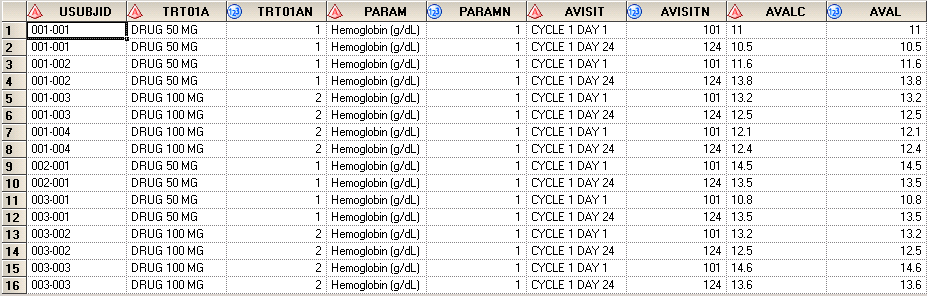
Get maximum number of digits after decimal point for values of each parameter
Both INDEX and SCAN functions are applied here to create a variable ln_. It stores the number of digits after decimal point of AVALC for each record.
Click here to hide/show code
data adlb;
set adlb;
if index(avalc,’.’)=0 then ln_ = 0;
else if index(avalc,’.’)>0 then ln_ = length(scan(strip(avalc),2,’.’));
run;
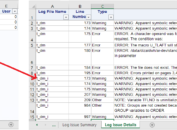
After running above code, you can get result data as below. In the first record, AVALC equals to 11. There is no decimal point and therefore ln_ equals to 0. For other records, there is only one digit after decimal point and thus the value of ln_ is set to be 1.
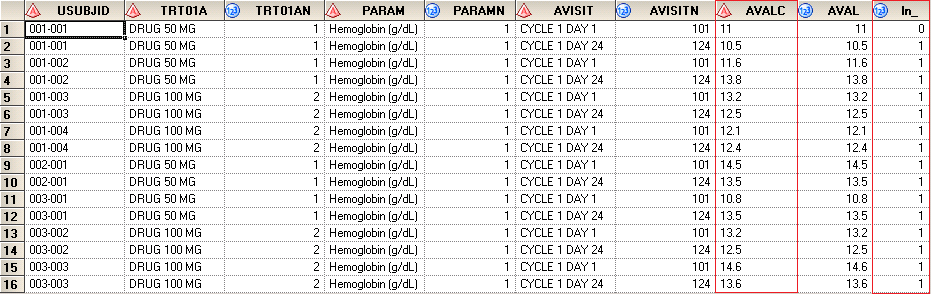
Now let’s use PROC SORT to sort data first by PARAMN (from A to Z), PARAM (from A to Z) and then by LN_ (from Z to A). Here are some explanations for RETAIN statement and FIRST.variable. RETAIN statement can be used to preserve a variable’s (here in our case is LN_) value from previous iteration of the DATA step. FIRST.variable is an automatic variable and it is only available when you are using a BY statement. The FIRST.variable is FIRST.PARAMN in our example. It means that FIRST.PARAMN will have a value of 1 for an observation with the first occurrence of a new value for PARAMN. For other observations, FIRST.PARAMN will have a value of 0. In our case, FIRST.PARAMN equals to 1 for the first observation (for which USUBJID equals to 001-001 and VISIT equals to CYCLE 1 DAY 24) and equals to 0 for other records. The value of LN_ for this first observation is 1 which is exactly what RETAIN statement will preserve. Therefore value of LN for all observations having PARAMN equals to 1 will be 1. This LN stores the maximum decimal places for the raw values of Hemoglobin test.
Click here to hide/show code
proc sort data = adlb; by paramn param descending ln_; run;
data adlb;
retain ln;
set adlb;
by paramn param descending ln_;
if first.paramn then ln = ln_;
ln1= strip(put((8 + ln*0.1),8.1));
ln2= strip(put((8 + ln*0.1 + 0.1),8.1));
ln3= strip(put((8 + ln*0.1 + 0.2),8.1));
run;
After getting the maximum decimal places for the raw values, we have to compute X, X+1 and X+2 per our rules. X equals to 1, X+1 equals to 2 and X+2 equals to 3. When converting numeric data into character data, we need a format. And here we create three formats stored in variables LN1, LN2 and LN3, respectively. LN1 will be used when converting MIN and MAX into characters. LN2 will be used when putting MEAN into characters while LN3 will be used when putting SD into characters.

Compute summary statistics
Both PROC SUMMARY and PROC MEAN can be used to derive summary statistics. Here we will use PROC MEAN to compute them.
Click here to hide/show code
ods exclude all;
proc sort data = adlb; by paramn param ln1 ln2 ln3 avisitn avisit trt01an; run;
proc means data = adlb n nmiss mean std min max median noprint;
by paramn param ln1 ln2 ln3 avisitn avisit trt01an ;
var aval;
output out = dist(drop = _type_ _freq_) n= n nmiss = nmiss mean = mean std = std
min=min max=max median = median;
run;
ods exclude none;
proc sort data = dist out= dummy(keep = paramn param ln1 ln2 ln3 avisitn avisit) nodupkey;
by param avisitn avisit; run;
data dummy;
set dummy;
do trt01an = 1 to 2;
n = .; nmiss = .; mean = .; std = .; min = .; max = .; median = .;
output;
end;
run;
proc sort data = dummy; by paramn param ln1 ln2 ln3 avisitn avisit trt01an; run;
proc sort data = dist; by paramn param ln1 ln2 ln3 avisitn avisit trt01an; run;
data dist;
length nn nnmiss $200. msd $200. med $200. mia $200.;
update dummy dist;
by paramn param ln1 ln2 ln3 avisitn avisit trt01an;
if n ne . then nn = strip(put(n,8.0));
else nn = “-“;
if nmiss ne . then nnmiss = strip(put(nmiss,8.0));
else nnmiss = “-“;
if mean ne . and std ne . then
msd = strip(putn(mean,ln2))||” (“||strip(putn(std,ln3))||”)”;
else if mean ne . and std eq . then
msd = strip(putn(mean,ln2));
else msd = “-“;
if median ne . then med = strip(putn(median,ln2));
else med = “-“;
if min ne . and max ne . then mia = strip(putn(min,ln1))||”, “||strip(putn(max,ln1));
else mia = “-“;
run;
data dat;
length col1 $200. ;
set dist;
array col{5} nn msd med mia nnmiss;
do i = 1 to 5;
seq = i + 1 ;
count = col{i};
id = trt01an + 1;
if i = 1 then col1 = “\li400 n”;
else if i = 2 then col1 = “\li400 Mean ” ||”(SD)”;
else if i = 3 then col1 = “\li400 Median”;
else if i = 4 then col1 = “\li400 Min, Max”;
else col1 = “\li400 Missing”;
output;
end;
keep seq col1 count paramn param avisitn avisit trt01an id;
run;
proc sort data = dat; by paramn param avisitn avisit seq col1 id ; run;
proc transpose data = dat out=final(drop=_name_) prefix = col;
by paramn param avisitn avisit seq col1 ;
id id;
var count;
quit;
By running above code, we can get below result. Here MEAN and MEDIAN have 2 decimal places, SD has 3 decimal places while MIN, MAX have 1 decimal places. This is exactly what we want. \li400 will be translated as two blank spaces when outputting following data into RTF.
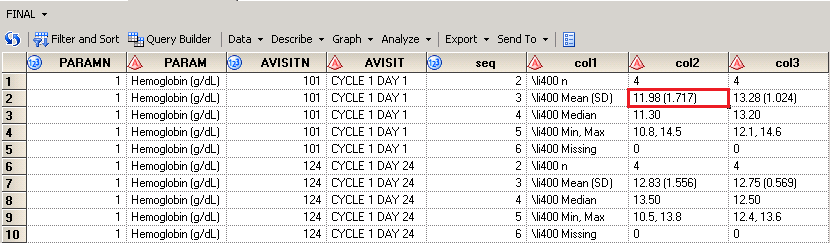
Verify the code with a slight different data
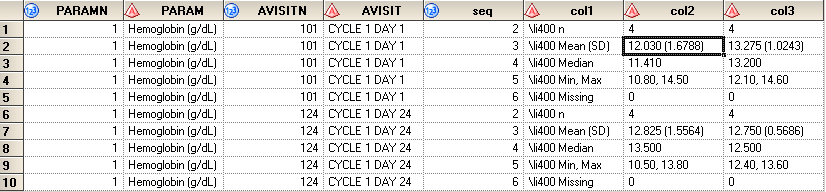
Now let’s change our ADLB using following code. The maximum number of digits after decimal point is no longer 1 now. It is 2 which implies that X equals to 2. MIN and MAX will have 2 decimal places. MEAN and MEDIAN will have 3 decimal places, SD will have 4 decimal places.
Click here to hide/show code
data adlb;
infile “D:\ADLB.txt”;
input USUBJID $ 1-7 TRT01A $ 9-20 TRT01AN 22 PARAM $ 25-41 PARAMN 43
AVISIT $ 45-60 AVISITN 62-65 AVALC $ 67-71 AVAL 73-76;
if _n_ = 1 then do; avalc = “11.22”; aval = 11.22; end;
run;
Here is the result output after running previous code on new ADLB. You can see that decimal places for MIN, MAX, MEAN, MEDIAN and SD have been changes automatically.

Let s tackle some more challenging problems that stretch our understanding of decimal place value. These problems involve regrouping place values in interesting ways.